Outlier analysis in data mining involves identifying and analyzing data points significantly different or deviating from the rest of the dataset. Outliers can be caused by various factors, such as data entry errors, unexpected events, etc., and their detection can lead to valuable insights and improve the accuracy of models. A wide range of techniques can be used for outlier analysis in data mining, such as statistical methods, clustering algorithms, and machine learning models.
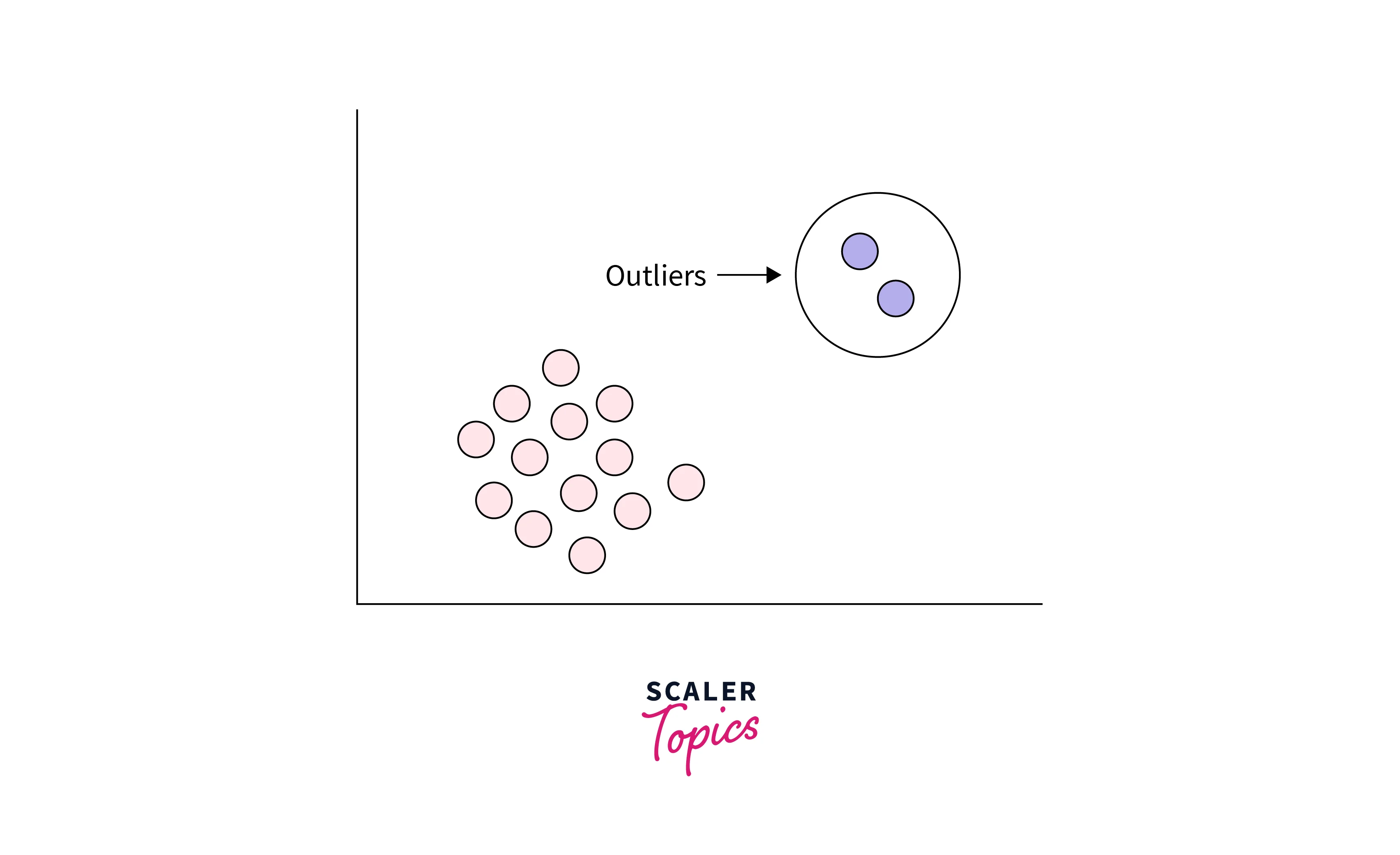
Outlier analysis in data mining is the process of identifying and examining data points that significantly differ from the rest of the dataset. An outlier can be defined as a data point that deviates significantly from the normal pattern or behavior of the data. Various factors, such as measurement errors, unexpected events, data processing errors, etc., can cause these outliers. For example, outliers are represented as red dots in the figure below, and you can see that they deviate significantly from the rest of the data points. Outliers are also often referred to as anomalies, aberrations, or irregularities.
The next question that comes to our mind is whether outliers are the same as noise in the data. Outliers and noise are fundamentally different concepts, so let’s understand how outliers differ from noise.
In data mining, noise refers to random variations or errors in the data that have no significant meaning or pattern. Noise can arise from various sources, such as measurement errors or data collection methods, and it can negatively affect the accuracy and reliability of data analysis. On the other hand, outliers can provide valuable insights and may need to be studied further, but they can also skew statistical analyses or predictive models if not handled properly.
Overall, the main difference between outliers and noise is that outliers are significant and potentially informative, while noise is insignificant and can be detrimental to data analysis.
Outlier analysis in data mining can provide several benefits, as mentioned below -
Let’s understand various types of outliers in the data mining process -
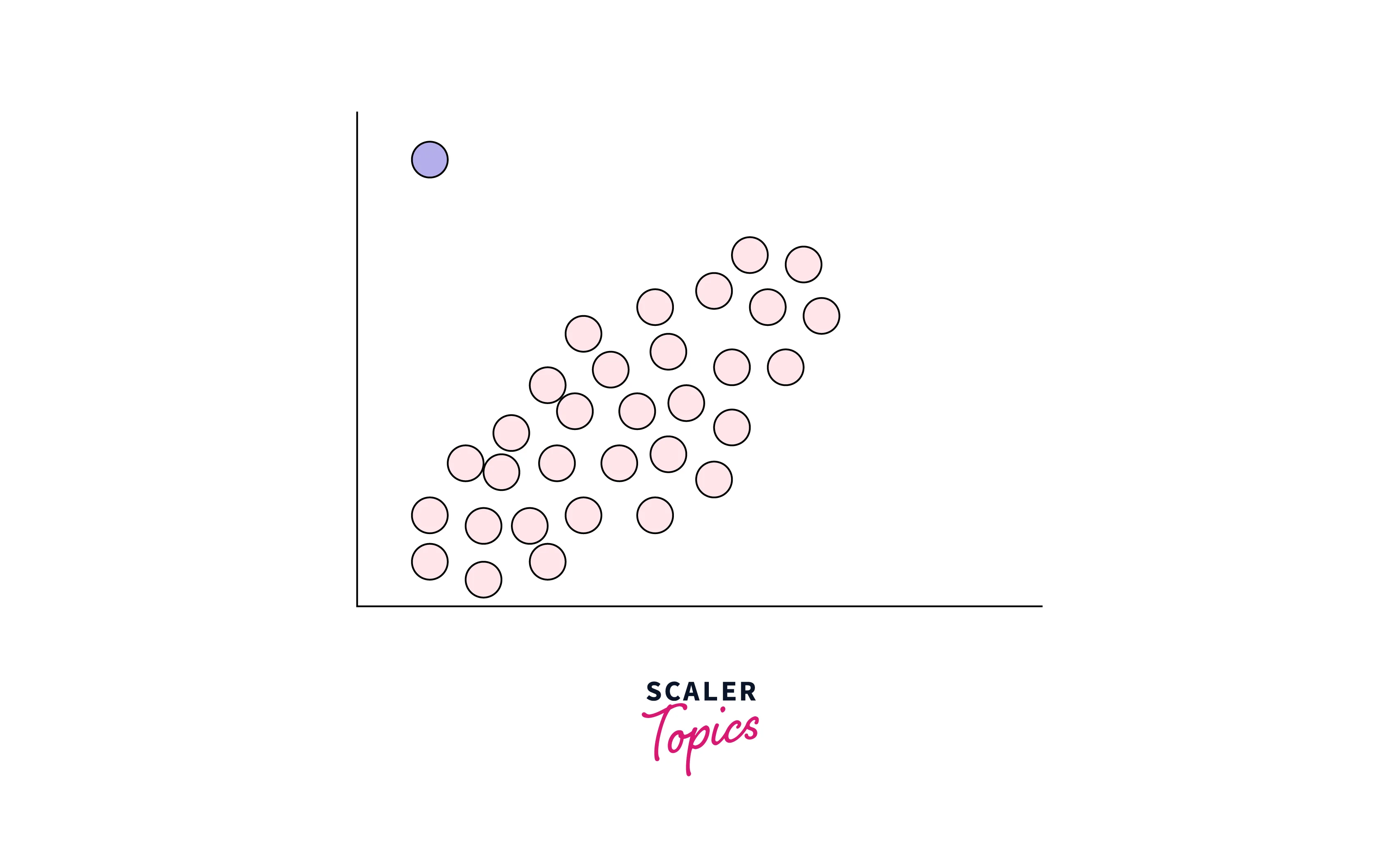
These are data points that are significantly different from the rest of the dataset in a global sense. Global outliers are typically detected using statistical methods focusing on the entire dataset's extreme values. For example, if we have a dataset of heights for a group of people, and one person is 7 feet tall while the rest of the heights range between 5 and 6 feet, the height of 7 feet would be a global outlier. An example of a global outlier is also shown below -
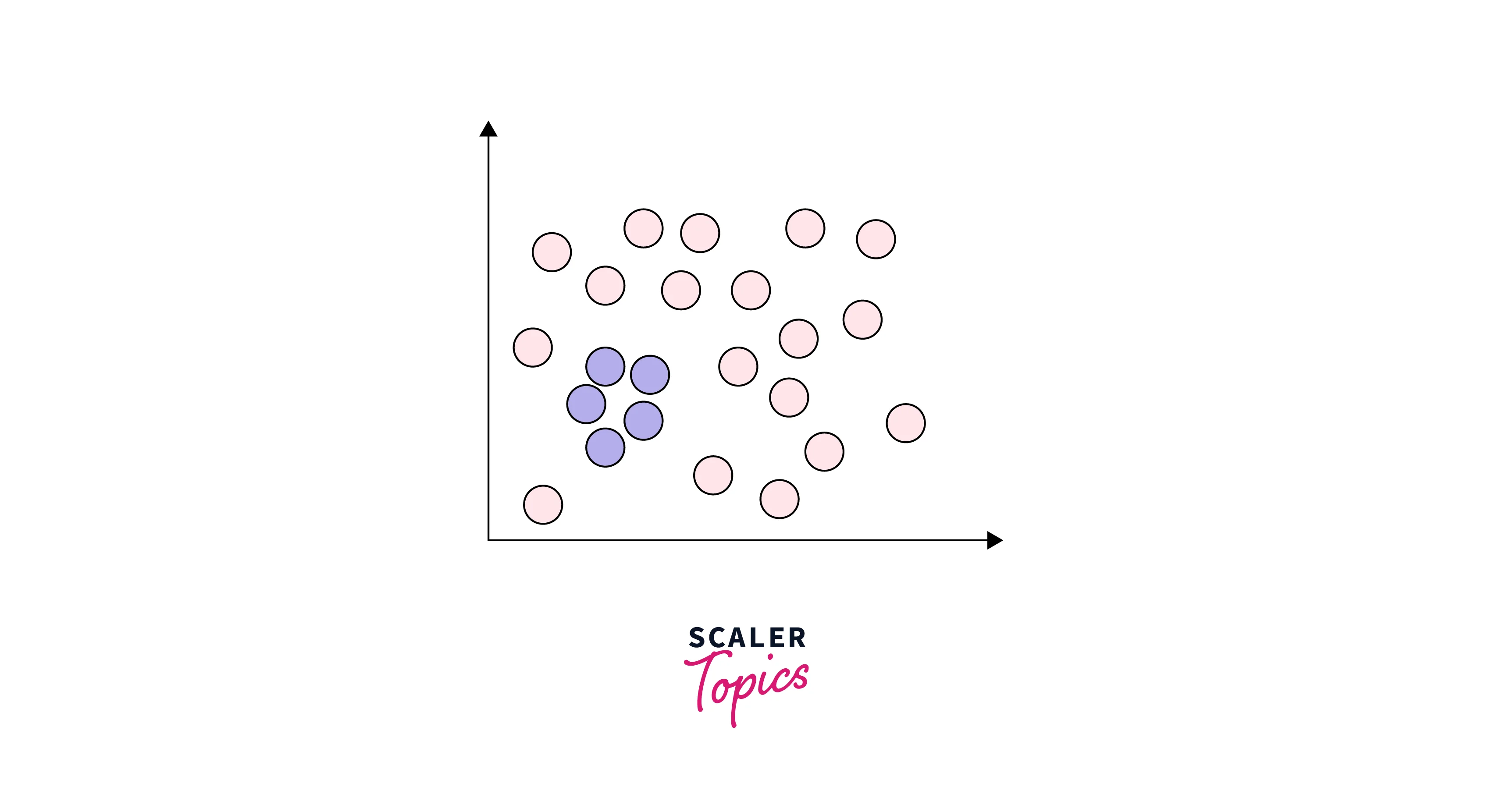
These are groups of data points that are significantly different from the rest of the dataset when considered together. Collective outliers are typically detected using clustering algorithms or other methods that group similar data points. For example, suppose we have a dataset of customer transactions, and a group of customers consistently makes purchases that are significantly larger than the rest of the customers. In that case, this group of customers could be considered a collective outlier. Similarly, in an intrusion detection system, the transmission of a DOS packet from one PC to another PC can be considered normal behavior, but if DOS packets are transmitted to many PCs at the same time, it would be considered as collective outliers.
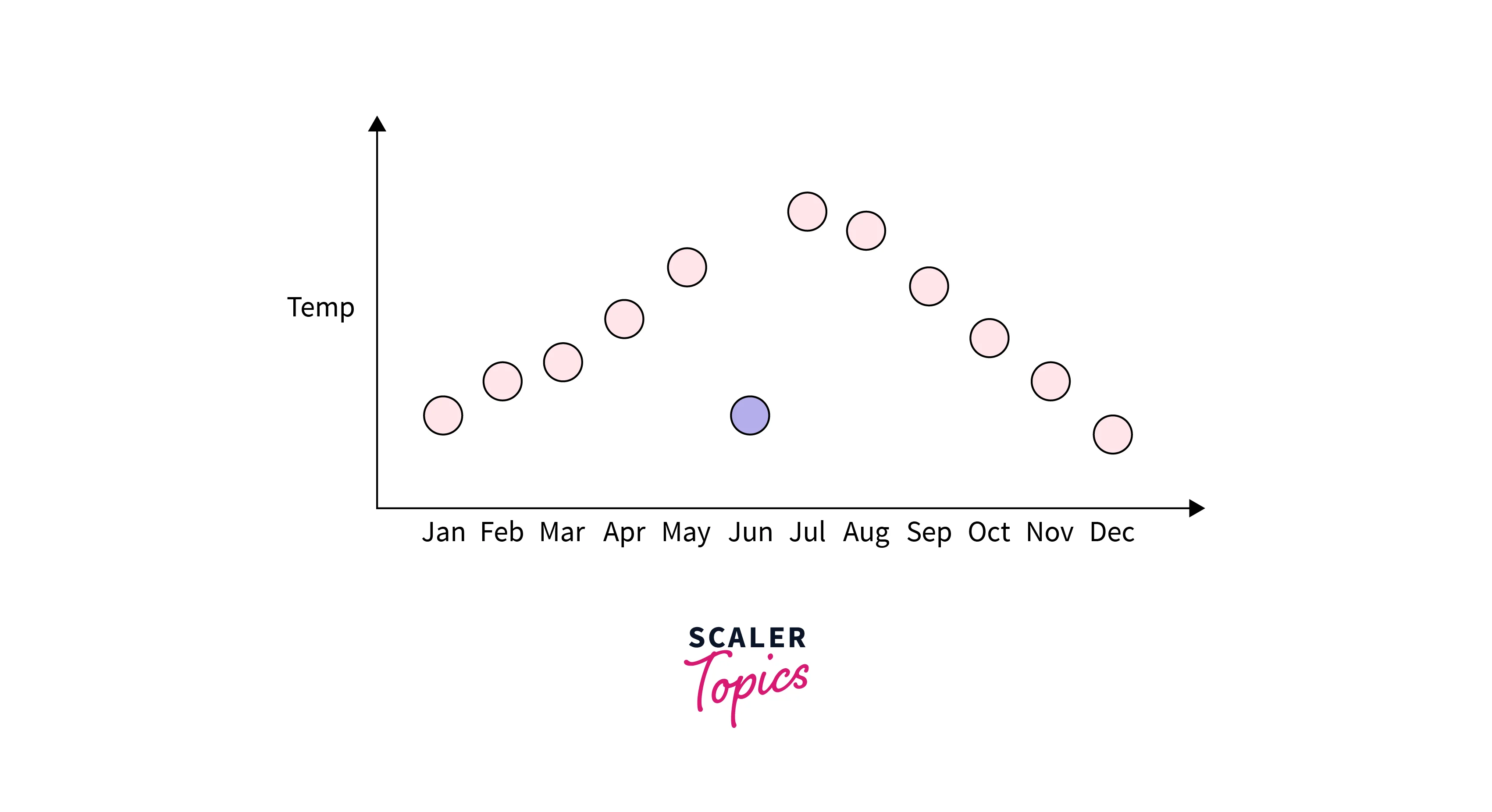
These data points significantly differ from the rest of the dataset in a specific context. Contextual outliers are typically detected using domain knowledge or contextual information relevant to the dataset. For example, if a city is recording 40-degree Celsius temperature, it may be considered normal in the summer and a contextual outlier in the winter. An example of a contextual outlier is shown below -
Eager to Explore Further in the Data Science Domain? Checkout Scaler's Data Science Courses and Master Data Science from Industry experts.
Outlier analysis is an important step in data mining as it helps identify and deal with anomalies in the data. Here are some steps involved in the outlier analysis -
In terms of when to do outlier analysis, it is typically performed as part of the data preprocessing phase before any modeling or analysis is carried out. Outlier analysis can be especially important when working with large datasets or complex data containing many different types of outliers. It is also important to re-evaluate outlier analysis periodically, as new data may reveal previously undetected outliers.
Outlier analysis has many applications in various fields, as mentioned below -
Q: What is an outlier in data mining?
A: In statistics, an outlier is an observation or data point that significantly differs from other observations in the dataset. Measurement errors, data entry errors, or legitimate deviations in the data can cause outliers.
Q: Why is outlier analysis important?
A: Outlier analysis is important because it can help identify anomalous data points that can affect the overall analysis and interpretation of the data. By detecting and handling outliers appropriately, data scientists can improve the accuracy and reliability of their results.
Don't just analyze data; master it. Join our Data Science free course and elevate your skills to tackle complex real-world challenges.